
정규화
제 1정규화
- 속성의 원자성을 확보한다
- 기본키를 설정한다
- 중복속성에 대한 분리가 1차 정규화의 대상이 되며, 로우단위의 중복도 1차 정규화의 대상이 되지만 칼럼 단위로 중복이 되는 경우도 1차 정규화의 대상이다
제 2정규화
- 기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거(분해)한다
제 3정규화
- 기본키를 제외한 칼럼간에 종속성을 제거한다
- 즉, 이행 함수 종속성을 제거한다
BCNF
- 기본키를 제외하고 후보키가 있는 경우, 후보키가 기본키를 종속시키면 분해한다.
반정규화
1. 반정규화를 통한 성능향상 전략
반정규화의 정의
- 데이터를 중복하여 성능을 향상시키기 위한 기법
- 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정
반정규화의 적용방법
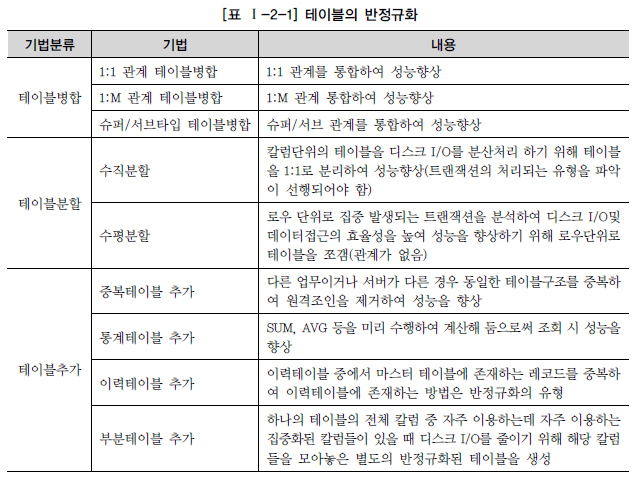
2. 반정규화의 기법


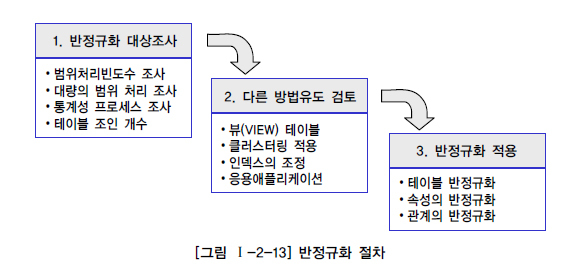
* 반정규화 절차
반정규화 대상조사
- 범위처리 빈도수 조사
- 대량의 범위 처리 조사
- 통계성 프로세스 조사
- 테이블 조인 개수
다른 방법 유도 검토
- 뷰 테이블
- 클러스터링 적용
- 인덱스의 조정
- 응용애플리케이션
반정규화 적용
- 테이블 반정규화
- 속성의 반정규화
- 관계의 반정규화
* 반정규화의 대상에 대해 다른 방법으로 처리
- 지나치게 많은 조인이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰를 사용하면 이를 해결할 수 있다
- 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우에 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상시킬 수 있다
- 대량의 데이터는 Primary key의 성격에 따라 부분적인 테이블로 분리할 수 있다. 즉. 파티셔닝 기법이 적용되어 성능저하를 방지할 수 있다.
- 응용 애플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능을 향상시킬 수 있다.
글에서 나오는 코드와 내용은 책 SQL 전문가 가이드에서 가져옴을 알립니다.
'📚CS > SQL' 카테고리의 다른 글
| 데이터 모델링의 이해 - 데이터 모델과 성능 & 분산 데이터베이스와 성능 (0) | 2023.07.23 |
|---|---|
| 데이터 모델링의 이해 - 대량 데이터에 따른 성능 (0) | 2023.07.23 |
| 데이터 모델링의 이해 - 성능 데이터 모델링의 개요 (0) | 2023.07.21 |
| 데이터 모델링의 이해 - 데이터 모델의 이해 (0) | 2023.07.21 |
| 데이터 모델링의 이해 - 식별자 (0) | 2023.07.20 |